
AIが生み出す速度を、
運用できる仕組みに
変える。
AI駆動開発の速度を活かしたまま、コード品質・レビュー・マージ・CI/CDを自動化・標準化。1万行から10万行まで、品質を保ったままスケールする運用基盤。
AI開発を持続可能にする3つの品質
コード品質
AI生成コードの重複実装、不要依存、複雑化を継続的に検知し、保守コストの増加を防ぎます。
プロセス品質
レビュー基準、マージ条件、Hotfix・Revert判断を標準化し、開発品質をチーム全体で維持します。
運用品質
CI/CD、staging、smoke test、production approvalを自動化し、安全なリリースを実現します。
あなたのコードベースを診断し、改善ポイントを可視化
約3営業日で、危険なコードや不要な依存、重複実装、複雑化している箇所を解析し、PDFレポートとしてお返しします。費用は一切かかりません。
リスク診断
重複・複雑度・不要依存を可視化
改善優先度
改善効果が高い箇所を優先順位化
保守性評価
将来の技術的負債と保守コストを予測
改善提案
具体的な改善アクションを提示
問題の発見から改善提案まで、無料で診断します。
Why Now
AI駆動開発の課題は、数ヶ月後に現れる。
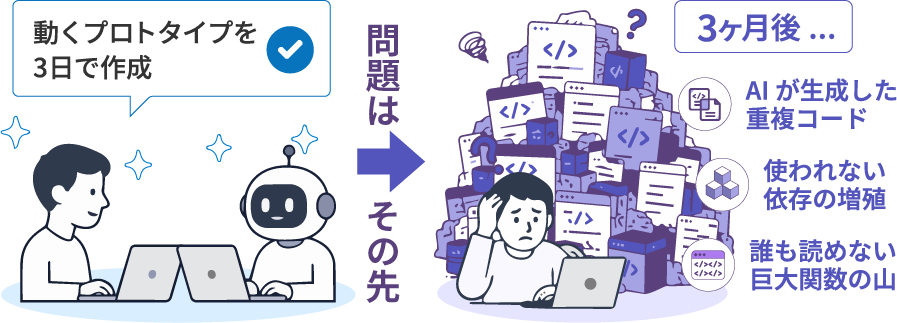
今のAIなら、3日で動くプロトタイプが作れます。問題はその先です。
3日で作れたものを3か月後に拡張しようとすると、AIが生成した重複コード・使われない依存・誰も読めない巨大関数の山に埋もれます。コードが1万行を超えた瞬間、人間のレビューでは追えなくなる。3万行を超えると「もう書き直したほうが早い」と全員が思い始めます。
これは"AIに任せた"ことが問題なのではなく、"AIに任せる前提のガバナンスがない"ことが問題です。
現場で起きている問題
AIを使った現場で、実際に起きていること。
コード品質崩壊
- 重複コード・依存の肥大化
AIは毎回ゼロから書くため同じ機能が複数箇所に生まれ、不要なライブラリが溜まり続ける - 仕様なき実装
「とりあえず動くもの」を先に作り、ドキュメントは翌日には嘘になる - テスト軽視
AIは動くコードは書けるが、テストは後回しになりリグレッションが本番で発覚する - 抑制コメント放置
// eslint-disable や # noqa が「いったん抑制」のつもりで貼られ、半年後も消えない
プロセス崩壊
- レビュー不能PR
AIが一度に2,000行生成。レビュアーはLGTM以外返せず、実質ノーチェックでマージされる - main直運用
レビューなし・自動検証なし。本番環境への反映が運任せになっている。 - マージ運用の崩壊
squash/merge/rebaseが混在し履歴が読めない。AIが自分のPRをそのままマージできてしまう - Hotfixが次の事故を生む
「緊急」を理由にCIをスキップし、修正が新たな障害を引き起こす
AI特有問題
- AIへの過信
AIの「自信ありげな間違い(ハルシネーション)」を検証せずマージ。本番で初めて誰も読んでいなかったと気づく - コンテキスト消失
セッションをまたぐたびに、毎回30分のコンテキスト再構築コストが発生している - ペアコーディング不全
「AIとペアプロ」が実態はAIが書いて人間がLGTMしただけ。役割定義も引き継ぎ儀式もない - シークレット混入
APIキーや接続文字列が平気でコミットされ、Slackでの謝罪と緊急ローテーションが定例化する
Framework
品質管理を、人とAIの両方で支える。
問題は、AIの開発速度が速すぎることではありません。AIが生成したコードを、いまだに人間の速度で品質管理しようとしていることです。
AI-Driven Development Framework は、品質管理そのものを自動化・標準化するための仕組みです。コード品質3層(予防・検知・掃除)とプロセス品質2本柱(ペアリング・マージゲート)の5要素が揃って初めて成立します。
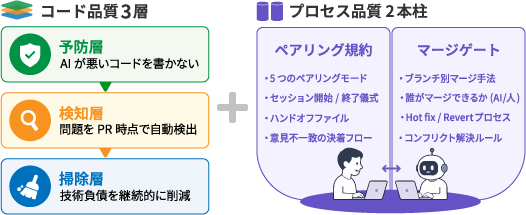
5つの品質レイヤー
設計からマージまで管理する。
予防層
AIがコードを書く前に、ルールを定義する。CLAUDE.md / AGENTS.md により、重複・無駄な依存・デバッグコード混入を防ぐ。
検知層
dead code、unused deps、巨大関数、重複コードをレビュー前にCIが自動検知する。
掃除層
技術負債は放置すると増殖する。週次オーディットと cleanup PR により、継続的に削減する。
ペアリング
AIが書いて、人間がLGTMするだけでは品質は保証できない。役割・開始・終了・引き継ぎをプロトコル化する。
マージゲート
誰でも、いつでも、main に入れてはいけない。マージ条件と責任を明文化する。
Cost Reduction
開発コスト削減が見込める理由
問題は、AIの開発速度が速すぎることではありません。
AIが生成したコードを、いまだに人間の速度で品質管理しようとしていることです。
機械的に判断できるものはCIへ。人間は設計と意思決定に集中できるようになります。
さらに影響分析・staging・smoke test・production approvalの4段階で、本番起因の事故を抑えます。
レビュー工数
当社想定ケースでの試算60分 → 15分
重複・dead code・未使用依存・複雑度などの機械的指摘をCIが吸収。人間レビュアーは設計判断とビジネスロジックだけに集中できます。※ 1PRあたりの平均レビュー時間の目安
本番障害コスト
当社想定ケースでの試算-50〜70%
影響分析 → staging自動デプロイ → smoke test → 本番手動承認の4段階で、リリース起因の事故を抑制します。※ ガバナンス層なし/あり開発の比較観測値
技術負債コスト
当社想定ケースでの試算-60〜80%
週次の Code Health Audit で負債が蓄積する前に検知・削減。1万行→10万行へのスケール時に必要だった「全面書き換え」が不要になります。※ 週次監査+cleanup PRによる継続的削減の試算
オンボーディング
当社想定ケースでの試算-50%
CLAUDE.md / AGENTS.md / STATUS.md を読めば、新メンバー(人もAIも)が即日から生産的に動けます。属人化した暗黙の作法が消えます。※ ルール文書化による立ち上がり期間の短縮
Case Study
AI駆動開発による
エンタープライズシステム構築事例
約1万人が利用するエンタープライズ向けイントラネットAIシステムを、
AIによる設計支援・実装支援・品質保証プロセスを活用し、約7週間で商用本番リリースしました。
AIチャット、施設予約、来客管理、Google Workspace連携、認証基盤、管理ポータルなど、
複数の業務システムを統合した大規模システムです。
約10,000人
利用者数
約7週間
開発期間
約25万行
コード規模
1,700件以上
コミット数
本プロジェクトではAIを単なるコード補完ツールとして利用したのではなく、
開発ライフサイクル全体に組み込み運用。
-
STEP 01
AI設計支援
API設計 / DB設計 / クラス設計 / シーケンス設計
-
STEP 02
AI実装支援
Backend生成 / Frontend生成 / SQL生成 / Migration生成
-
STEP 03
AI品質保証
コードレビュー / テスト生成 / セキュリティレビュー / 静的解析
-
STEP 04
商用本番運用
CI/CD / Pull Request検証 / リリース / 運用改善
AI活用領域
品質保証プロセス
従来開発:約6〜14ヶ月
AI駆動開発:約7週間
生産性向上:約4~8倍
本事例の成功要因は、単なるコード生成ではなく、「AIによる開発」と「AIによる多段階品質保証プロセス」を組み込んだAI駆動開発として設計した点にあります。AIコードレビュー、AIテスト生成、AIデバッグ、CI/CD、自動品質チェックを組み合わせることで、短期間でありながら商用本番リリースを実現しました。
Reality Check
メリット / デメリット
メリット
- 初期開発 3〜5倍速:仕様駆動+並列ペアセッションで、従来「2週間」の機能が3〜5日で動く
- 開発コスト半減:手戻り・レビュー・障害・技術負債・オンボーディングの複合効果
- 少人数で大規模運用:5人で50,000 LOCのSaaSを維持できる
- コードが腐らない:1万行→10万行でも「全面書き換え」が不要
- ドキュメントが副産物として生まれる:仕様・決定・負債・ペアセッションが自然に文書化される
- AI活用が属人化しない:プロジェクトが変わっても同じプロセスが使える再現性
- 監査対応力:誰が承認・マージしたか、人間かAIか、すべて追跡可能
デメリット・前提条件
- 初期セットアップコスト:新規は半日、既存(数万行規模)は1日+チーム適応1〜2週間
- プロセス規律が必須:「面倒だから --no-verify で push」する文化では何を入れても効かない
- CI実行時間・料金が増加:code-health検査で+3〜10分、Actions料金が月数百〜数千円増
- 偽陽性のチューニング期間:knip / vulture / jscpdのsuppression整備に1〜2週間
- AIサービスへの依存:Claude / Cursor / Actions 障害時に生産性が落ちる
- シニアエンジニアの文化的抵抗:「AIに書かせるなんて」は実在する反応。巻き込み設計が必要
- ハルシネーションはゼロにならない:レビュアーAI+人間の二重チェックで吸収するが完全排除は不可
Fit
このフレームワークが効果を発揮する組織
向いている
- AIを既に使っているがガバナンスがない開発組織
- 数万行〜数十万行の中規模SaaS・業務システム
- 少人数(2〜10人)で素早く動きたいスタートアップ
- 既存プロダクトの再生・延命を狙うチーム
- 受託開発で品質と速度を両立させたい開発会社
- 社内ツール・DX推進でAIガバナンスが追いついていない情シス部門
向いていない
- 「AIは禁止」という文化の組織
- 数百行で完結するスクリプト・PoC
- 100人超のエンタープライズ(別途、既存プロセスとの統合設計が必要)
- 半年以内に廃止予定のレガシーシステム
- 単発・1か月以内のスポット案件
Package
導入時に整備するもの
プロジェクトの状況に合わせて、AI開発ルール、品質ゲート、CI/CD、レビュー運用を設計・導入します。以下は代表的な支援項目です。
AI開発ルール設計
- AIに任せる範囲、禁止事項、実装前の確認事項を定義
- 重複実装、不要依存、デバッグコード混入を予防
開発プロセス設計
- AIと人間の役割、レビュー基準、引き継ぎ方法を標準化
- ペアセッションの開始・終了・記録方法を設計
品質ゲート構築
- PR品質チェック、重複コード検知、未使用依存検知を自動化
- 複雑度・巨大PR・抑制コメントを継続的に監視
CI/CD整備
- staging、自動テスト、smoke test、本番承認フローを整備
- Hotfix・Revert時の判断基準と安全策を明文化
技術負債管理
- 週次コード監査、改善優先度、cleanup PRの運用を設計
- 将来の保守コストを見える化し、継続的に削減
テンプレート整備
- PR、Issue、Hotfix、Revertなどの判断基準をテンプレート化
- 属人化した暗黙ルールを、チームで再利用できる形に整理
※ 実際の提供内容は、リポジトリ構成、開発体制、既存CI/CD、利用AIツールに合わせて個別に設計します。必要に応じて、AIルールファイル、PRテンプレート、GitHub Actions、技術負債管理ドキュメントなどを整備します。
診断の流れ
無料解析の流れ
まずは現在のコードベースを解析し、どこに技術負債や運用リスクが潜んでいるのかを可視化。
導入の判断はレポート確認後で構いません。
- STEP 01 解析申請 フォームから申請。GitHubリポジトリまたはZIPファイルを共有
- STEP 02 アクセス共有 read-only権限を付与。安全な環境でコードベースを確認
- STEP 03 コード解析 重複コード、未使用依存、複雑度、PR運用状況を分析
- STEP 04 レポート作成 改善優先度を整理し、PDFレポートを3営業日以内に作成
- STEP 05 改善提案・開発支援 解析結果を共有し、改善提案から導入・開発支援まで対応
無料解析(3営業日)
- GitHubリポジトリまたはZIPファイルを共有
- コード品質・依存関係・重複率・複雑度を解析
- 経営層向けサマリーと技術詳細をレポート化
- PDFレポートを納品
- 希望に応じて導入支援・開発支援も可能
解析後の支援内容
- Framework導入支援
- 既存コードベース改善
- 技術負債削減プロジェクト
- AI開発体制構築
- CI/CD整備
- AI駆動開発支援
Free Analysis
あなたのコードベースに潜むリスクを可視化します。
3営業日で、危険なコードや不要な依存、重複実装、複雑化している箇所を解析し、PDFレポートとしてお返しします。費用は一切かかりません。
解析でわかること
- 死んだコード(dead code):dead exports・到達不能ブランチの行数と上位ファイル
- 使われていない依存(unused dependencies):削除可能なライブラリ数と削減サイズ目安
- コード重複率(duplicate rate):重複箇所トップ10と全体比率
- 複雑度ホットスポット(complexity hotspot):循環複雑度(CCN)10超の関数一覧
- マージ運用の健全性(merge health):自己承認PR数・平均レビュアー数・Hotfix比率
- 巨大PR率:500行超PR比率(≒レビュー不能PR率)と改善見込み
- 削減見込み試算:推定削減LOC・依存数・ビルド時間
提出物
- PDFレポート:経営層向け1枚サマリ+エンジニア向け技術詳細
- rawデータ(CSV / JSON):自分たちで深掘り可能なデータ一式
- 30分の解説ミーティング(希望される場合のみ)
必要なもの
- GitHubリポジトリへのread-onlyアクセス、またはZIPアップロード
- 事前準備一切不要
FAQ
よくある質問
モノレポでも対応可能ですか?
可能です。サブディレクトリ単位での解析にも対応します。
10万行を超える規模でも解析できますか?
可能です。所要日数が伸びる場合は申請時にお伝えします(通常+2〜3営業日)。
コードや解析データは外部に持ち出されますか?
解析中のみ隔離環境にコピーし、レポート提出後72時間以内に破棄します。NDA締結対応も可能です。
既存のCI/CDと競合しませんか?
競合しません。既存のワークフローと並列で動く設計です。対象外の検査は自動でスキップされます。